
Audiobooks have become increasingly popular in recent years due to their convenience and compatibility with modern lifestyles. Whether listening during your daily commute or while doing household chores, audiobooks allow individuals to immerse themselves in their favorite stories while on-the-go.
However, creating an audiobook typically requires a significant investment of both time and money. This is where text to speech technology comes in, providing an innovative solution for authors and publishers alike.
What is Text to Speech?
Text to speech is a technology that allows written text to be converted into spoken words. This is achieved through a process called speech synthesis, which utilizes various algorithms and voice databases to generate realistic, human-like speech. Text to speech technology has been used for a variety of applications, including language translation, accessibility, and now, audiobook creation.
How does Text to Speech work?
Text to speech works by analyzing written text and breaking it down into individual phonetic units, called phonemes. These phonemes are then combined to create words, sentences, and ultimately, the spoken text. Text to speech software utilizes machine learning to continuously improve the accuracy and naturalness of the synthesized voice, resulting in more realistic AI voices over time.
Components of a TTS system
A TTS system consists of two main components: text analysis and speech synthesis.
- Text analysis is the process of extracting linguistic information from the input text, such as phonetic transcription, prosody, and punctuation. Text analysis can be further divided into two sub-components: text normalization and text-to-phoneme conversion. Text normalization is the process of converting non-standard words, such as numbers, abbreviations, acronyms, and idioms, into their full forms. For example, “Dr.” becomes “doctor”, “10” becomes “ten”, and “LOL” becomes “laughing out loud”. Text normalization can be done using regular grammars or lexicons. Text-to-phoneme conversion is the process of assigning phonetic symbols to each word in the text, based on its spelling and context. For example, “read” can be pronounced as /riːd/ or /rɛd/, depending on its tense. Text-to-phoneme conversion can be done using letter-to-sound rules or morpho-syntactic analysis.
- Speech synthesis is the process of generating speech signals from the linguistic information produced by text analysis. Speech synthesis can be done using various methods, such as concatenation, parametric, or neural network-based approaches. Concatenation is the method of joining pre-recorded speech units, such as words, syllables, or phonemes, to form continuous speech. The quality of concatenation depends on the size and selection of the speech units, as well as the smoothing techniques used to reduce discontinuities. Parametric is the method of using a mathematical model of the human vocal tract and other voice characteristics to generate synthetic speech. The parameters of the model are derived from the linguistic information and modified by prosody rules. The quality of parametric synthesis depends on the accuracy and naturalness of the model. Neural network-based is the method of using a deep learning algorithm to learn the mapping between linguistic information and speech signals from a large corpus of speech data. The neural network can generate high-quality and natural-sounding speech with minimal human intervention. However, this method requires a lot of computational resources and data
What are the benefits of Text to Speech?
Text to speech technology offers a wide range of benefits, especially for audiobook creation. Firstly, it eliminates the need for expensive recording studios, sound engineers, and voice actors, making the production process significantly more cost-efficient. Additionally, text to speech allows authors and publishers to customize their books in terms of reading speed and even accents, opening up possibilities for diverse and inclusive audiobook offerings.
Accessibility and inclusivity are important values for creating a more equitable and diverse society. Text-to-speech (TTS) technology can play a vital role in enhancing accessibility and inclusivity for a wider audience, especially for audiobooks.
TTS is the technology that converts written text into spoken speech, using artificial or natural voices. TTS can make audiobooks available to people who may have difficulty reading or accessing written content, such as people with visual impairments, dyslexia, ADHD, or other cognitive or learning disabilities.
TTS can also make audiobooks more inclusive for people who speak different languages or have different accents, by providing a variety of voices and languages to choose from.
Some of the benefits of TTS for audiobooks are:
- TTS can improve comprehension and retention of information, by providing an auditory reinforcement of the written content
- TTS can increase engagement and enjoyment of audiobooks, by providing natural and expressive voices that match the tone and mood of the content
- TTS can reduce the cost and complexity of producing audiobooks, by using automated and scalable solutions that do not require human narrators or studios
- TTS can expand the availability and diversity of audiobooks, by enabling authors and publishers to create audiobooks for any genre, topic, or language
TTS is a powerful tool that can make audiobooks more accessible and inclusive for all. By using TTS, audiobook listeners can experience the joy of reading in a way that suits their needs and preferences.
Can Text to Speech be used for audiobooks?
Yes, text to speech technology can be used for audiobook creation. In fact, it has become increasingly popular in recent years use text to speech for audiobooks due to its cost-effectiveness and versatility. With text to speech software, any written content, including books, PDFs, web pages, and text files, can be easily converted into an audio file, such as an MP3 or WAV, for a seamless audiobook experience.
How to Use AI Voice Generator for Audiobooks
What is an AI Voice Generator?
An AI voice generator is a type of text to speech software that utilizes artificial intelligence to create more realistic and natural-sounding voices. AI voice generators, such as VOICEAIR, UberTTS, Speechify or Lovo, offer a range of customizations, including reading speed, pitch, and even the ability to choose a specific accent or voice based on regional dialects. AI voice generators allow for improved voice flexibility, resulting in more engaging audiobooks.
What are the best Text to Speech software for audiobooks?
When it comes to selecting text to speech software for audiobooks, there are a variety of options available. Some of the best text to speech software options include Amazon’s Polly, Google’s Text-to-Speech, and Apple’s built-in text to voice feature. These software options allow authors and publishers to easily convert any text into speech and create high-quality audiobook productions.
UberTTS is of the powerful text to speech generator for audiobooks which combines the AI capabilities of both Amazon Polly and Google Text to speech along with Azure & IBM voices.
Alternatively you can use other popular speech converters like:
- NaturalReader: A cloud-based solution that supports a range of files and languages, and allows you to download audio files. It has a free tier and a paid tier with more features.
- Murf: A web-based tool that lets you create realistic voice-overs for videos using AI. You can customize the voice, emotion, speed, and background music. It has a free trial and a subscription plan.
- Amazon Polly: A service that provides lifelike voices using deep learning. You can use it to create speech-enabled applications and products, such as podcasts, e-learning courses, and games. It has a pay-as-you-go pricing model.
- Play.ht: A platform that helps you convert your blog posts and articles into audio using human-like voices. You can embed the audio on your website or share it on social media. It has a free plan and a premium plan with more benefits.
- Voice Dream Reader: An app that reads any text aloud with natural sounding voices. You can import documents from various sources, adjust the reading speed and voice, and listen offline. It is available for iOS and Android devices.
How can AI Voice help you create audiobooks?
AI Voice offers a range of benefits for audiobook creation, primarily due to its ability to generate more natural and realistic-sounding speech. This can result in a more enjoyable and immersive listening experience for audiences. Additionally, AI voice allows for increased speed and efficiency in the production process, as there is no need for extensive post-production editing.
Using Text to Speech Software for Audiobooks
What are the best Text to Speech for audiobooks?
As previously mentioned, some of the best text to speech software for audiobooks include Amazon’s Polly, Google’s Text-to-Speech, and Apple’s built-in text to voice feature. Additionally, there are a range of specialized text to speech software options available, such as NaturalReader and ReadSpeaker, that offer more advanced customization options.
How can Text to Speech software help you customize your audiobooks?
Text to speech software allows authors and publishers to easily customize their audiobook productions in a variety of ways. This includes adjusting the reading speed, pitch, and volume to create the optimal listening experience. Additionally, text to speech software allows for different accents and regional dialects to be used, making the audiobook more accessible and inclusive.
Can Text to Speech software help you create natural-sounding audiobooks with different accents?
Yes, text to speech software can help create natural-sounding audiobooks with different accents. This is achieved by utilizing voice databases that include a range of regional dialects and accent options. This allows for greater voice flexibility and a more diverse selection of audiobooks for audiences.
Convert Text to Audiobooks
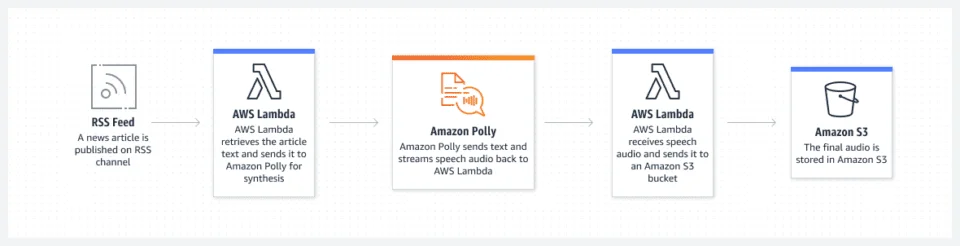 Pin
PinHow to convert PDFs into audiobooks using Text to Speech technology?
Converting PDFs into audiobooks using text to speech technology is a simple process. Firstly, select your preferred text to speech software and upload the PDF document. The software will then analyze the text and convert it into spoken words, creating an audio file that can be downloaded in a variety of formats. This allows individuals to easily convert written content into an audiobook format for a more versatile reading experience.
What are the best audiobook platforms for using Text to Speech technology?
There are a variety of audiobook platforms that are compatible with text to speech technology. One of the most popular options is the Amazon-owned Audible. Audible offers a range of audiobooks that are compatible with text to speech software, allowing for a more customizable listening experience. Other popular platforms include Apple Books and Google Play Books.
What are the benefits of using Audiobooks with Text to Speech technology?
There are a variety of benefits to using audiobooks with text to speech technology. Firstly, it allows individuals to easily convert any written content into an audio format for greater accessibility. Secondly, text to speech technology allows for greater voice flexibility and can create natural-sounding audiobooks with different accents, resulting in a more inclusive and diverse selection of audiobooks for audiences.
Best Practices for Using Text to Speech in Audiobook Production
Below are some possible best practices for using text to speech in audiobook production are:
Choose a text to speech tool that offers a variety of natural-sounding and expressive voices that suit the genre, audience, and purpose of the audiobook. You can also customize the voice features such as tone, pitch, speed, and volume to match the mood and emotion of the text.
Convert the written content into an audio format using a voice synthesizer. This will give you an idea of how the text sounds and identify any errors, inconsistencies, or ambiguities that need to be corrected or clarified3. You can also use the audio as a reference for your own narration or editing.
Edit the audio content to enhance its quality and clarity. You can use audio editing software to trim, cut, splice, merge, or adjust the audio segments. You can also add sound effects, music, or background noise to create a more immersive and realistic listening experience.
Test the audio content with different devices, platforms, and listeners. You can use different headphones, speakers, or media players to check the sound quality and compatibility of the audio content. You can also ask for feedback from potential listeners or experts to evaluate the effectiveness and appeal of the audio content.
Combining Text to Speech and Human Narration for Audiobooks
Combining Text to Speech and Human Narration for Audiobooks is a topic that explores how to use artificial intelligence to create high-quality audiobooks from text files. It is a technology that can make audiobook production more accessible, affordable and diverse for authors and publishers. Some examples of services that offer this technology are Apple Books digital narration and Google Play Books auto-narrated audiobooks.
These services use advanced speech synthesis and natural language processing to generate realistic and expressive voices that can narrate different genres of books. They also allow authors and publishers to retain the rights to their audiobooks and distribute them through various platforms.
However, these services also face some challenges and limitations, such as ensuring the accuracy, quality and consistency of the narration, respecting the creative choices and preferences of the authors and narrators, and competing with the human-narrated audiobook market that still values the magic and artistry of human voices.
Understanding the hybrid approach: Integrating TTS and human narration in audiobook production.
The hybrid approach: Integrating TTS and human narration in audiobook production is a research paper that proposes a novel method to combine two types of text-to-speech (TTS) synthesis: concatenative TTS (CTTS) and statistical TTS (STTS). CTTS uses natural speech segments from a recorded database, while STTS generates speech features from a statistical model.
The paper argues that CTTS can produce natural and high-quality speech, but it may suffer from discontinuities and data limitations. On the other hand, STTS can produce smooth and consistent speech, but it may sound muffled and unnatural.
The paper suggests that by using a hybrid dynamic path algorithm, it is possible to construct an utterance representation that interweaves natural segments and model-generated segments, thus taking advantage of both approaches. The paper reports listening tests that demonstrate the validity and effectiveness of the proposed method.
Benefits of using TTS as a drafting and proofing tool for human narrators
Using TTS as a drafting and proofing tool for human narrators can have several benefits, such as:
- It can help human narrators to prepare and practice their scripts before recording, by allowing them to listen to how the text sounds and identify any errors, inconsistencies, or ambiguities that need to be corrected or clarified.
- It can help human narrators to enhance their performance and delivery, by providing them with feedback on their pronunciation, intonation, pace, and expression, and by suggesting ways to improve their voice quality and emotion.
- It can help human narrators to save time and money, by reducing the need for multiple recordings and edits, and by enabling them to work remotely and collaboratively with other narrators, editors, and producers.
- It can help human narrators to create more diverse and inclusive audiobooks, by allowing them to experiment with different voices, accents, languages, and styles that suit the genre, audience, and purpose of the audiobook
Achieving a seamless blend: Strategies for combining TTS and human narration effectively
Some possible strategies for combining TTS and human narration effectively are:
- Use TTS as a drafting and proofing tool for human narrators, by allowing them to listen to how the text sounds and identify any errors, inconsistencies, or ambiguities that need to be corrected or clarified1. TTS can also provide feedback on pronunciation, intonation, pace, and expression, and suggest ways to improve voice quality and emotion.
- Use TTS as the foundation for audio content, which can then be enhanced with the addition of human voice actors. Human voice actors can bring a level of authenticity and personalization to audio content that cannot be achieved through TTS alone. They can interpret scripts and convey emotional tones and nuances that are difficult to capture with TTS. Human voice actors can also adjust their delivery based on audience feedback, which further enhances the personalization and effectiveness of the audio content.
- Use TTS to generate a base narration track for multimedia content, which can then be customized and enhanced with the addition of human voice actors in various languages. This approach streamlines the localization process and reduces production costs, while also delivering high-quality, personalized audio content to global audiences.
Examples of successful audiobooks that employ the hybrid approach
Let’s look into some possible examples of sci-fi audiobooks that use the hybrid approach:
- Upgrade Soul by Ezra Claytan Daniels, narrated by Marcia Gay Harden, Wendell Pierce, and others. This is an audio adaptation of a graphic novel that uses a mix of natural speech segments and model-generated segments to create a realistic and expressive narration. The story follows an elderly couple who undergo an experimental procedure to rejuvenate their bodies and minds, but end up with horrifying results.
- How High We Go in the Dark by Sequoia Nagamatsu, narrated by a full cast. This is a sci-fi novel that uses a full cast of voice actors to bring to life multiple stories, characters, and places that interconnect in complex and satisfying ways. The story spans centuries and continents, exploring how humanity copes with a pandemic that causes people to emit light when they die.
- Gideon the Ninth by Tamsyn Muir, narrated by Moira Quirk. This is a sci-fi fantasy novel that uses a single voice actor to deliver a stunning performance that captures the humor, horror, and heart of the story. The story follows Gideon, a swordswoman who accompanies her necromancer mistress to a haunted palace where they must compete with other necromancers for a prize.
The hybrid approach enhances these audiobooks by creating a more immersive and engaging listening experience for the audience. By combining natural speech segments and model-generated segments, the hybrid approach can produce natural and high-quality speech that matches the tone and mood of the story.
By using a full cast of voice actors, the hybrid approach can create a diverse and inclusive audio content that reflects the variety of characters and perspectives in the story. By using a single voice actor, the hybrid approach can create a personalized and emotionally nuanced audio content that conveys the personality and voice of the narrator.
The hybrid approach can also make the audiobooks more accessible and adaptable to different languages, platforms, and devices.
What Does the Future of Audiobooks Look Like with AI?
How can AI improve audiobooks in the future?
AI has the potential to significantly improve the audiobook experience in a variety of ways. Firstly, AI can help create even more natural-sounding voices and accents, resulting in a more immersive and realistic listening experience.
Additionally, AI has the ability to dynamically optimize audiobooks based on the listener’s preferences, such as adjusting the reading speed or tone.
Finally, AI has the ability to personalize the audiobook experience, creating unique productions tailored to individual listeners based on their listening history and preferences.
What new features can be expected in 2023?
It is difficult to predict exactly what new features will be released in 2023, but it can be assumed that AI will continue to play a significant role in the evolution of audiobooks. New features may include improved voice databases, greater voice flexibility, and enhanced post-production editing tools for even more tailored and personalized listening experiences.
Will voice actors be replaced by AI-generated voices?
While AI-generated voices are becoming increasingly realistic, it is unlikely that they will completely replace voice actors in the near future. Voice actors still offer a range of benefits, including greater emotional depth and versatility in their performances.
However, AI-generated voices will continue to play an important role in audiobook production, particularly with more technical or educational content where natural-sounding speech is a priority over unique voice characteristics.
Frequently Asked Questions (FAQs)
What is text-to-speech?
Text-to-speech is a technology that allows for the conversion of written text into spoken words.
How does text-to-speech work for audiobooks?
Text-to-speech technology can be used to turn text from an e-book or PDF into an audio file that can be played as an audiobook. This can provide an accessible listening experience for those who prefer listening to reading, or who have visual impairments.
What are the benefits of using text-to-speech for audiobooks?
Text-to-speech can offer a faster and more convenient way to listen to audiobooks. It allows for greater customization, as listeners can choose the voice and speed of the narration, and can even pause, rewind, or skip sections as needed.
How can I use text-to-speech technology to create my own audiobooks?
There are various tools and software available that allow for the easy conversion of text to speech. Some may require a fee or subscription, while others could be free or open source.
What is the best text-to-speech tool for audiobooks?
There are many text-to-speech tools available in the market, each with their own unique features and benefits. Some popular options include VOICEAIR, UberTTS, Speechify, NaturalReader, and Balabolka.
How can I choose the best text-to-speech voice?
Most text-to-speech tools offer a wide selection of voices to choose from, ranging from natural human voices to advanced AI text-to-speech generators. You can select the AI voice that best suits your preferences and needs or you can choose from a collection of AI voices.
Can text-to-speech technology be used to convert text to audio for other purposes?
Yes, text-to-speech can be used to turn printed text for several purposes like podcasts, presentations, video narration, voice overs, whether for personal or commercial use.
What is the difference between text-to-speech and a voice actor for audiobooks?
While text-to-speech technology can provide a fast and cost-effective way to create audiobooks, some argue that a human voice actor can provide a more immersive and emotional listening experience.
How does text-to-speech affect the listening experience for audiobooks?
Like any tool, text-to-speech can enhance or detract from the listening experience for audiobooks depending on the quality of the voice, the accuracy of the narration, and the preferences of the listener.
What are some tips for using text-to-speech for the best listening experience?
Some tips for using text-to-speech for the best listening experience include selecting a great text to speech tool, choosing a high-quality voice, and adjusting the speed and tone of the speech to match your preferences.


